Andrew Ng. Deep Learning Course 2 Improving Deep Neural Networks 过拟合部分的笔记。
高方差(high variance) 对应的问题就是 过拟合(overfitting),模型在训练集上表现的非常完美,然而开发集和测试集却有很高的错误率。这时需要引入正则或者多加些数据来调优。这一篇就来讲过拟合的处理方法。方差/偏差的解释戳会议笔记 - Nuts and Bolts of Applying Deep Learning
Regularization
正则化(Regularization) 是最常见的方法之一。在深度学习中的正则化中,我们保留所有的 unit,但是会压缩其权重。
Loss function
对损失函数加上一个正则化参数,一般形式
其中 $\Omega(\theta)$ 是参数范数惩罚,$\alpha \in [0,+\infty)$ 是参数范数惩罚程度的超参数,$\alpha=0$ 代表没有正则化,$\alpha$ 越大正则化惩罚越大。
$\Omega(\theta)$ 有 L1 和 L2 范式,如果用 L1,W 最终会是稀疏的,也就是说 W 中会有很多 0;L2 参数正则化通常被称为权重衰减(weight decay),实际过程中一般用的是 L2。
$L1: \ \ \ \ \Omega(\theta)=||w||_1$
$L2: \ \ \ \ \Omega(\theta)={1 \over 2}||w||^2_2$
在原来的损失函数基础上加上正则因子:
权重更新: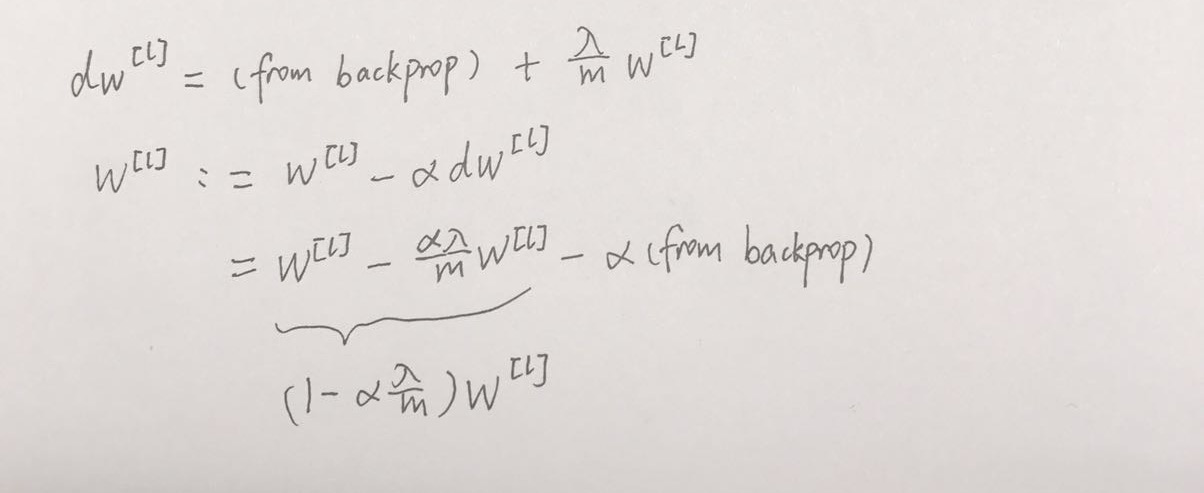
$min_{w^{[1]},b{[1]},…w^{[L]},b{[L]}, }J(w,b)={1 \over m}\sum^m_{i=1}L(\hat y_{(i)}, y^{(i)}) + {\lambda \over 2m}\sum^L_{l=1}||w||^2_2$
发现加入 L2 后,每次梯度更新前权重会先乘以 $1-\alpha {\lambda \over m} $,相当于收缩了权重,因此 L2 正则也叫权重衰减(weight decay)。
这里的正则化参数$\lambda$通常使用 dev_set 来配置。
Why regularization
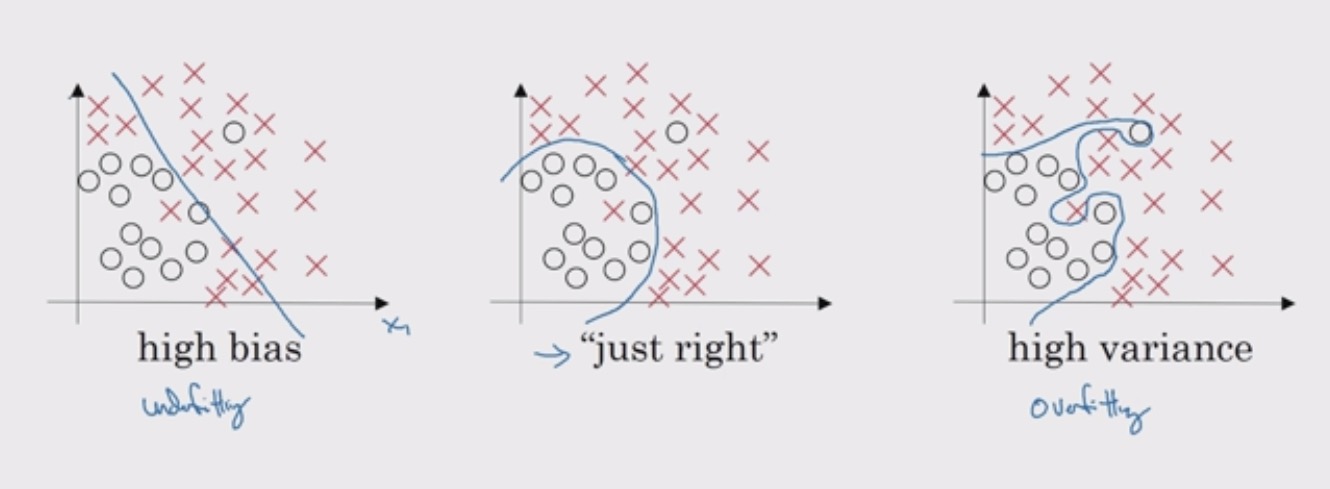
一个直观上的理解是如果 $\lambda$ 足够大,由上一部分的计算可以得出 W 接近于 0,也就是说很多 hidden units 的权重被降成了 0,这就消除了很多 hidden units 的影响,实际上就是从下面右图的结构转换到了左图。当然事实上并不能说消除了这些 hidden units 的影响,只能说是减少,网络变得更简单罢了。
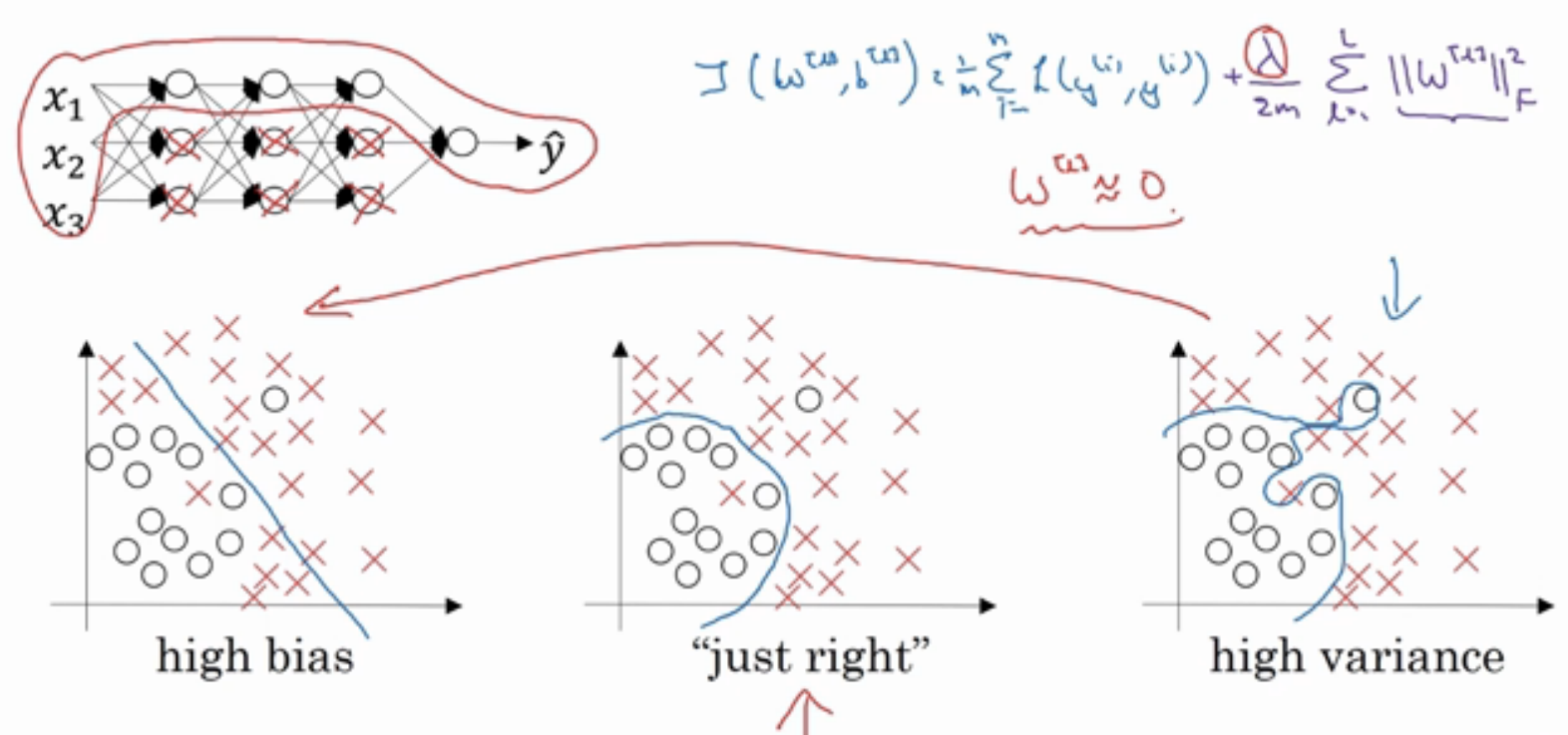
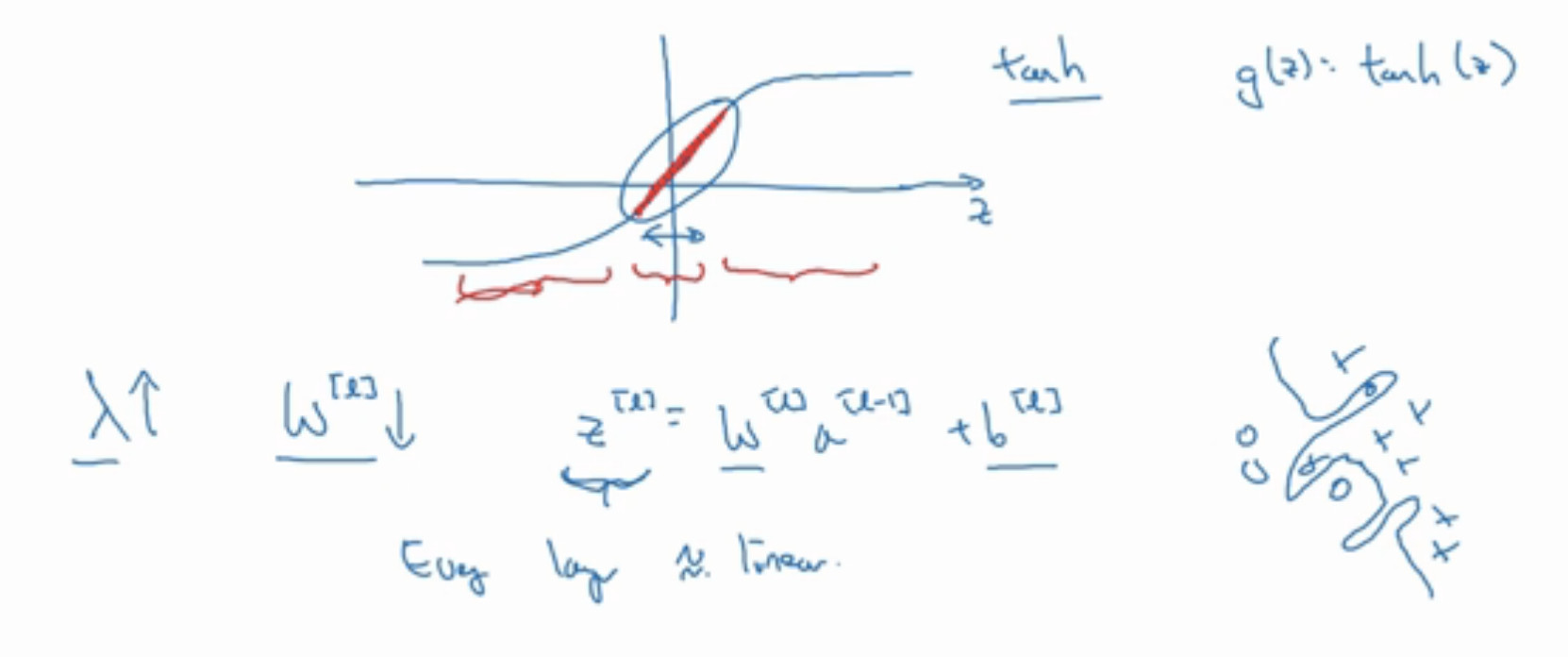
从另一个角度考虑,$\lambda$ 变大 => $W^{[l]}$ 变小 => z 变小,看一下激活函数,以 tanh 为例,在 z 小的部分,曲线趋于线性,计算接近线性函数的值。如果每一层都是线性的话,那么无论网络有多少层,输出都是输入的线性组合而已,当然就不会过拟合啦。所以说在需要做复杂的决策的时候,$\lambda$ 不能设太大。另外使用 L2 正则需要搜索合适的 $\lambda$,花费很大。
Dropout
另一种方法是 Dropout,随机删除一些 unit。Dropout 会遍历网络每一层,设置消除网络中节点的概率,对待删除的节点,删除从该节点进出的连线,得到一个节点更少、规模更小的网络,然后用 BP 对这个新的小的网络训练,持续这个过程。因为丢弃的神经元在训练阶段对 BP 算法的前向和后向阶段都没有贡献,所以每一次训练都像是在训练一个新的网络。
这里要讲的是 Inverted dropout,看下代码,keep_prob 表示保留任意一个 hidden unit 的概率,清除任意一个 hidden unit 的概率是 1-keep_prob,在网络第三层,过程如下
|
|
没有第三行就只是普通的 dropout,在这种情况下,测试阶段我们必须关闭 dropout 模式,去模拟训练阶段的集成网络模型,因为我们不希望最后结果是随机的,不希望预测结果受到干扰。而加了第三行就变成了 inverted dropout,我们只要在训练阶段缩放激活函数的输出值,而不用在测试阶段改变什么(只用修改一个参数)。举个例子,第三层有 50 个 units,keep_prob=0.8,有 10% 的 units 被消除了,那么在下一层,$z^{[4]}=w^{[4]}*a^{[3]}+b^{[4]}$,$a^{[3]}$ 的大小减少了 20%,为了让 $z^[4]$ 的期望值不变,或者说 $a^{[3]}$ 的期望值不变,需要补上这 20%,所以 $w^{[4]}*a^{[3]}/0.8$。
Why dropout
很直接的思路,每次迭代网络都变小了,自然就减少了过拟合的可能。另一种解释是,dropout 使得神经网络不能依靠任何一个特征,因为每个特征都有可能被随机清除,这样的将结果是网络不会给一个 unit 特别大的权重,而是会 spread out weight,给每个 unit 都增加一点权重。而分散所有权重其实就产生了和 L2 类似的压缩权重的效果。
相对于 L2 正则,dropout 可以处理多样化的输入,然而 dropout 方法不会阻止参数过大,参数之间也不会互相牵制,所以有时需要配合使用 L2 或者其他正则化来改变这个情况。
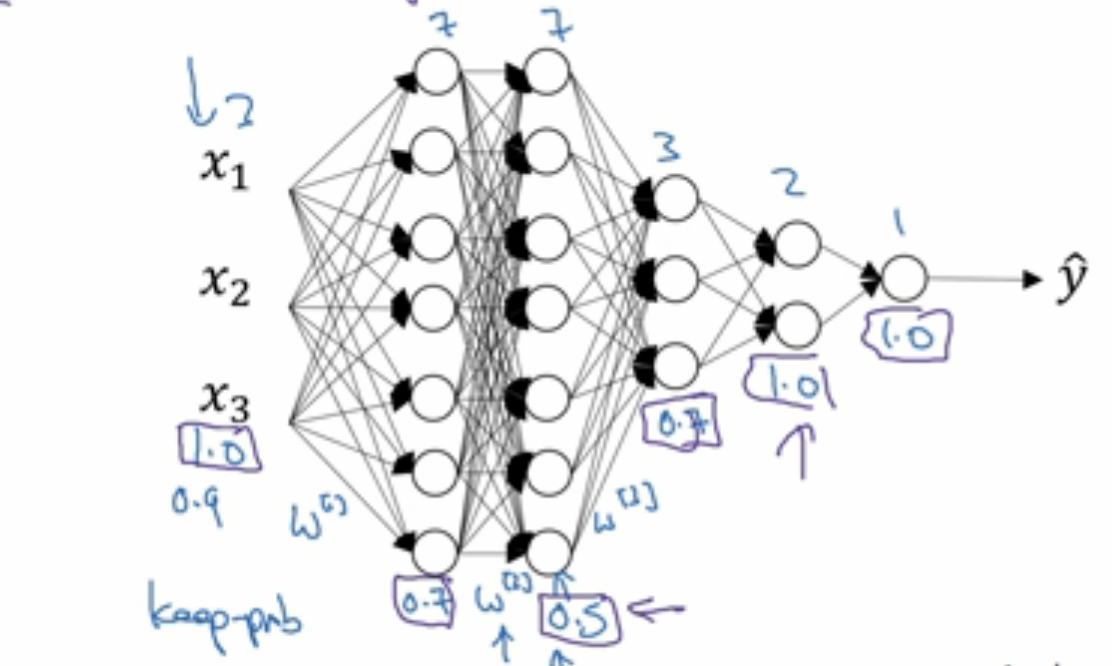
另外提到的一个技巧是,可以对不同层设置不同的 keep_prob。如下图,第一层 W 矩阵是 3x7,过拟合的可能性小一些,可以留下 70% 的 unit,第二层是 7x7,更可能过拟合,所以少保留一些,设 keep_prob=0.5,由此类推,给每一层设定不同的 keep_prob,对不需要担心过拟合的层,直接设为 1。
还有要注意的是,dropout 开启的情况下损失函数不再是定义良好的,也就没法根据损失函数的效果图来 debug,所以一般在看代码有没有 bug 的时候先会关闭 dropout。
Others
- Data Augmentation
解决过拟合的另一个思路是使用更多的数据,所以当数据量不够的时候,会进行数据增强。- 数据集的各种变换,如对图像的平移、旋转、缩放、裁剪、扭曲变形。
- 在输入层注入噪声,如去噪自编码器,通过将随机噪声添加到输入再进行训练能够大大改善神经网络的健壮性。
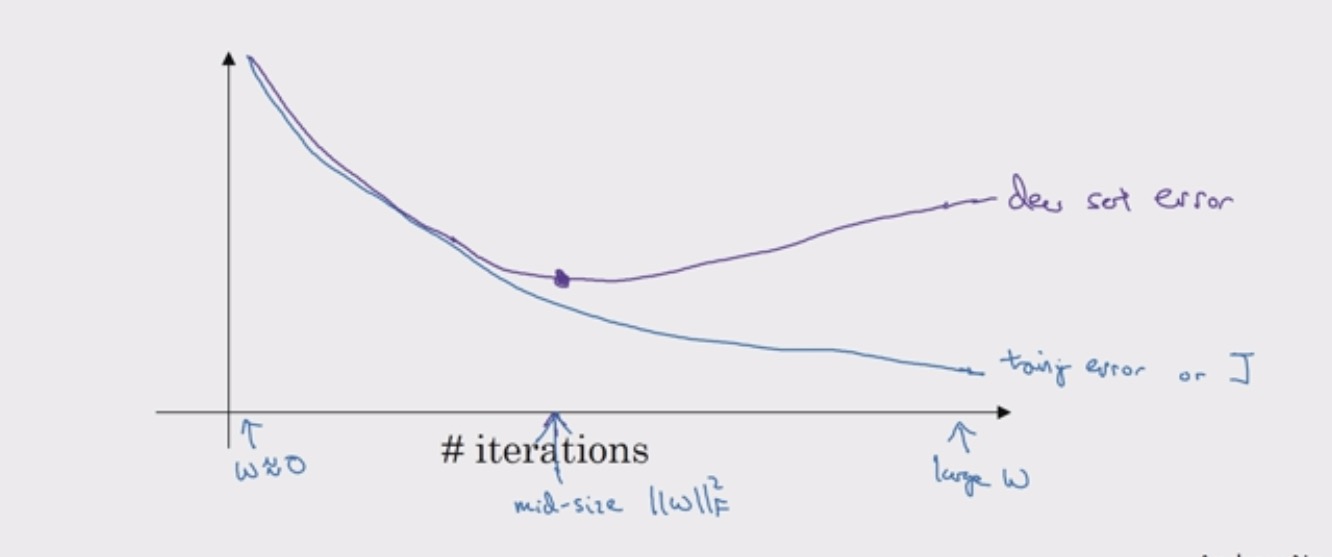
- Early Stopping
同时画出 train error 和 dev error,会发现 dev error 先下降然后到某个点会上升,所以在迭代到某次觉得结果不错的时候,提前停止训练。
w 在最开始的时候值很小,到后面的时候会很大,在中间的时候可能得到一个中等大小的 Frobenius norm,和 L2 正则相似,我们要选择 W 范数较小的神经网络。找 small, large, middle 几个点,不用像 L2 正则那样尝试很多的 $\lambda$ 参数,这时 early stopping 的优势,然而过早的停止可能对损失函数 J 的优化不到位,loss 不够小。